<linux 内存管理模型>
下面这个图将Linux内存管理基本上描述完了,但是显得有点复杂,接下来一部分一部分的解析。
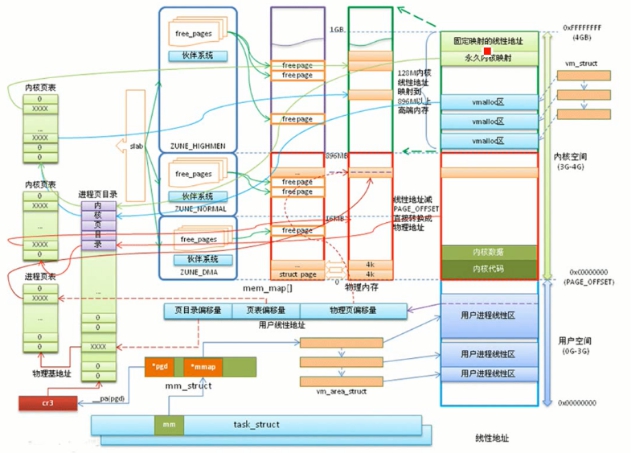
内存管理系统可以分为两部分,分别是内核空间内存管理和用户空间内存管理:
内存管理子系统的职责是:进程请求内存时分配可用内存,进程释放内存后回收内存,以及跟踪系统内存使用情况。现代操作系统要求能够使多个程序共享系统资源,同时要求内存限制对于开发者是透明的。在这种情况下,虚拟内存应运而生。虚拟内存可以使得进程可以访问比实际内存大得多的空间,并且使得多个程序共享内存显得更加有效。
当程序从内存中取得数据的时候,需要使用地址指出需要访问的内存位置(注意:这个地址是虚拟地址,他们组成的进程的虚拟地址空间)。每个进程都有自己的虚拟地址空间,这样做的好处是可以防止非法读取或覆盖其他进程的数据(虚拟地址允许进程使用超过物理内存的内存空间,因此操作系统可以给每个进程提供独立的虚拟线性地址空间。)
a:作为内存管理的基本单元,页的许多状态需要被记录下来(比如,内核需要知道什么时候可以被回收),因此内核为内核中的每个页都准备了页描述符struct page{}.系统在初始化时根据物理内存的大小建立起一个page结构数组mem_map,作为物理页面的“仓库”。
b:struct page
{
unsigned long flags;//32位的位图,每一位表示页面的一个属性
atomic_t count ;//统计页面正在被都少个进程使用,为0时表示可以回收。
struct list_head list;//页表的双向链表
struct address_space *mapping;
unsigned long index;
struct list_head lru;//链接最少使用的页表,可能会被回收
union{
struct pte_chain *chain;
pte_addr_t direct
}pte;
unsigned long private;
#if definde (WANT_PAGE_VIRTUAL)
void *virtual;//指向页面的虚拟地址
#endif
}
<系统在内存中的分布示意图>
a:4G进程地址空间解析
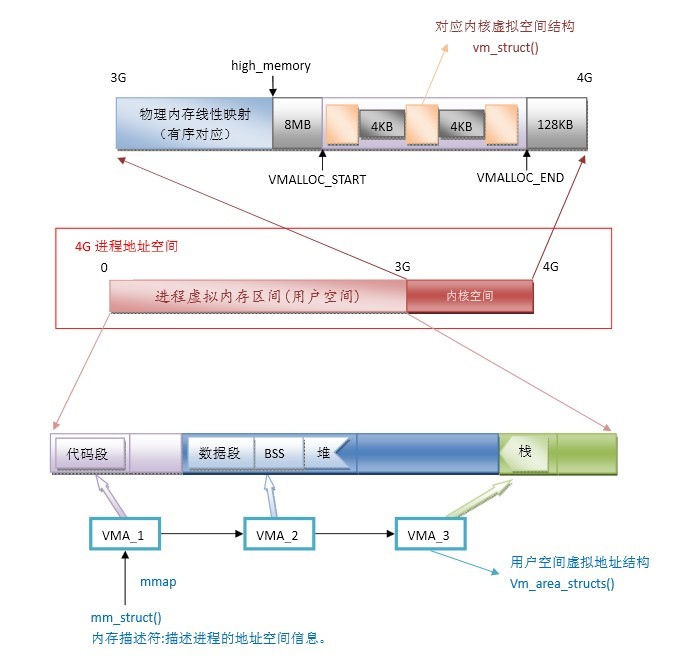
b:虚拟地址空间分配及其与物理内存对应图
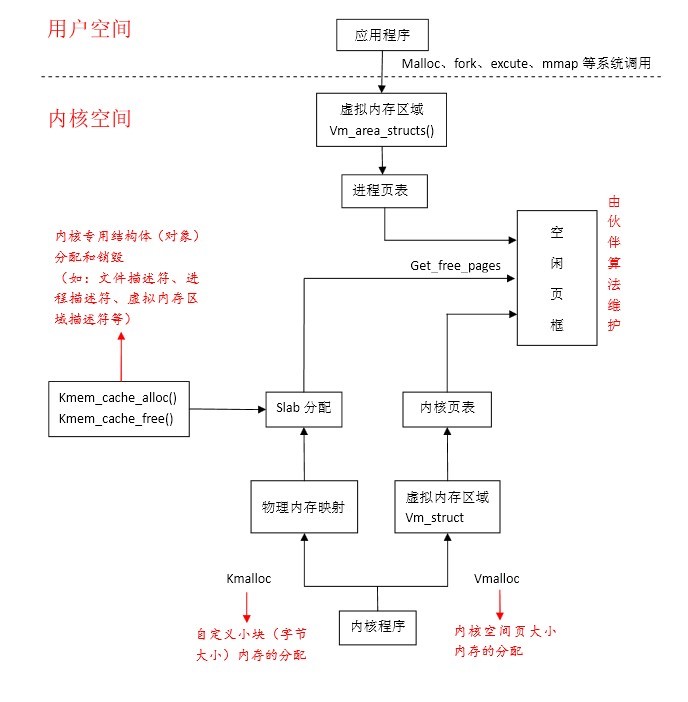
其中kmalloc和vmalloc函数申请的空间对应着不同的区域,同时又不同的含义。
c:物理内存分布图
如下图所示,Linux系统启动后,整个系统在物理内存中的结构如图所示,和虚拟内存结构图相比还是有很大的区别的,图中的ZONE_HIMEN也就是系统的用户空间了。
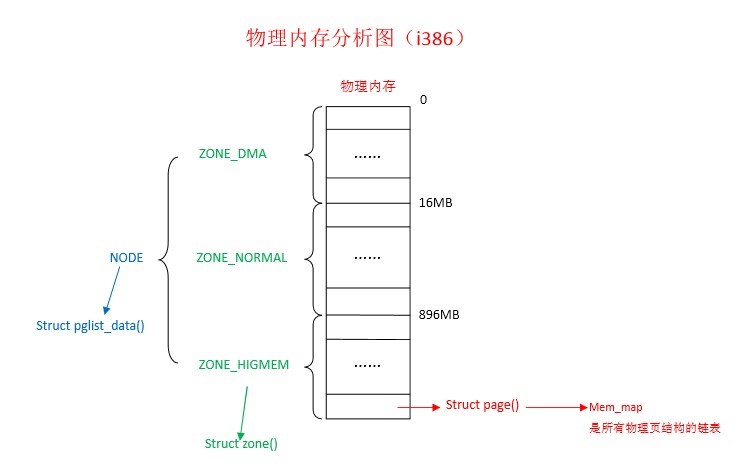
物理地址有896M直接映射到虚拟地址的内存空间,这是一一对应的映射,只有起始地址不一样,偏移是一样的。个大小大多是固定的,哪怕你的内存超过一个G,太小了就另外说了,当你内存很大的时候,超过896M时,剩余的那些内存怎么办呢?这多出来的叫做高端内存,如果你使用vmalloc申请空间,就会在高端内存中分配,如果你使用kmalloc申请空间,就会在小于896的内存中分配。所以还是很讲究的。
<内核空间内存管理>
a:操作系统的生命周期可以分为两个阶段:
————自举阶段:
自举阶段使用临时内存(系统刚刚启动的时候)
————正常运行阶段:
即熊启动完成后,系统正常运行的阶段
b:正常运行阶段又分为两个部分:
固定分配部分:
这部分是有固定的内存分配给内核代码和数据。
动态请求部分:
为动态内存请求分配内存,动态请求源自于进程的创建和空间的扩张。
c:内存管理区
并非所有的内核空间的内存区域都会被公平对待,对内核中的不同内存的使用是有限制的。内存管理的区是由页面组成的,Linux内核将内核空间分为3个内存管理区:
ZONE_DMA:用于分配DMA页面请求
ZONE_NORMAL:具有虚拟映射的非DMA页面区间
ZONE_HIHGMEN:高端内存区间
c:内存空间管理区描述符
与内核管理的的所有对象一样,每个内存管理区都有一个叫做zone的结构体,其中存放内存管理区的所有信息,记录这内存管理区的使用情况.
struct zone {
unsigned long watermark[NR_WMARK];
unsigned long percpu_drift_mark;
unsigned longlowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
unsigned longmin_unmapped_pages;
unsigned longmin_slab_pages;
#endif
struct per_cpu_pageset __percpu *pageset;
spinlock_tlock;
int all_unreclaimable;
#ifdef CONFIG_MEMORY_HOTPLUG
seqlock_tspan_seqlock;
#endif
struct free_areafree_area[MAX_ORDER];
#ifndef CONFIG_SPARSEMEM
unsigned long*pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
#ifdef CONFIG_COMPACTION
unsigned intcompact_considered;
unsigned intcompact_defer_shift;
#endif
ZONE_PADDING(_pad1_)
spinlock_tlru_lock;
struct zone_lru {
struct list_head list;
} lru[NR_LRU_LISTS];
struct zone_reclaim_stat reclaim_stat;
unsigned longpages_scanned;
unsigned longflags;
atomic_long_tvm_stat[NR_VM_ZONE_STAT_ITEMS];
unsigned int inactive_ratio;
ZONE_PADDING(_pad2_)
wait_queue_head_t* wait_table;
unsigned longwait_table_hash_nr_entries;
unsigned longwait_table_bits;
struct pglist_data*zone_pgdat;
unsigned longzone_start_pfn;
unsigned longspanned_pages;
unsigned longpresent_pages;
const char*name;
} ____cacheline_internodealigned_in_smp;
d:内存管理区操作辅助函数
(2)for_each_zone()
遍历系统中的所有内存管理区
(2)is_highmem()和is_normal()
连个函数检测内存是否位于该内存管理区
e:页面请求函数
------页面是存放页的基本内存单元(其实就是很多的页组成了页面),只要进程请求内存,内核只要满足要求就会给其分配页面。同理,只要进程不在需要页面,内核就会将其回收。
(1)返回指向pages结构体的指针,(返回void* 类型)(该结构体对应分配的请求页面)
alloc_page()//该函数用于请求单页
alloc_pages()//该函数用于请求4个页面
(2)返回32为虚拟地址,该地址是分配页面的首地址
__get_free_page()/__get_dma_pages()
f:释放请求页面
__free_page()/__free_pages()
g:伙伴系统(伙伴算法)
-------每当页面被分配和回收的时候,系统都会遇到外部碎片或内存碎片的问题(即页面散布在内存中,即使可用页面足够多,但是无法分配大块的连续页面)。为了解决这个问题,Linux系统提供了伙伴算法。
h:伙伴算法原理
伙伴系统把内存中空闲块组成链表,将不同大小的空闲内存块组织起来(我猜测是将相同大小的组织在一起),虽然大小不一样,但是都是2的幂次方。当系统中有进程释放没存的时候,伙伴系统就会搜索与所释放块大小相等的可用空闲内存块,如果找到相邻的空闲块,就将其合并成两倍于自身大小的块。这种合并的块称为伙伴。
i:分配与释放页面源代码
(1)分配页面



(2)释放页面
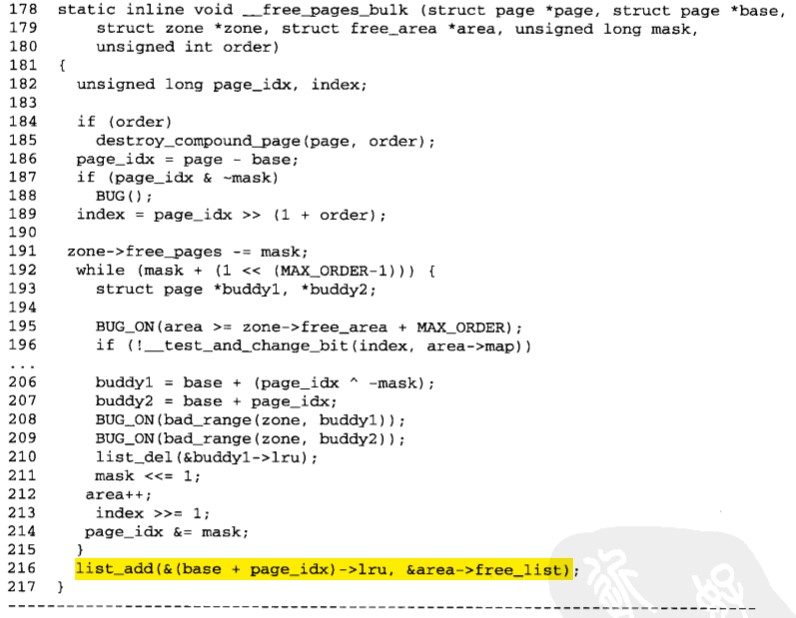
注意:代码细节详见《Linux内核编程》P130.
k:slab分配器
我们知道页是Linux内存管理的基本单元。但是进程往往会以字节的为单位请求内存,如果照样给其分配一个页面,这样显得浪费内存,为了解决这个问题并实这种小块内存请求。内核开发者们实现了slab分配器。
slab分配器为了减少内存分配,初始化,销毁和释放的代价,通常会把经常使用的内存区以缓存的方式对待,并加以维护(即比如系统经常会使用task_struct ,这就将该结构体以缓存方式常驻内存),当进程不在需要该内存区时,就会把该内存放入缓冲区。
由此可见,slab时间上由许多缓存组成。缓存分为"专用"和"通用"。专用缓存保存特定对象的内存区,比如各种描述符,比如进程描述符"struct task_structs".
注意:关于slab的详细信息,见《Linux内核编程》P130
<用户空间/进程内存管理>
以上讨论了内核如何管理自己的内存空间,接下来讨论用户空间如何让管理自己的内存空间。用户进程创建后需要分配一个虚拟地址空间,并且可用通过增加或删除地址间隔得以扩大或缩小。(地址间隔(一段地址空间):是一种内存单元,也被称作内存范围或内存区,把进程地址空间划分为不同的区域是有用的,不同的区域具有不同的保护方案和访问属性,比如".text"".data"".bss""栈""栈")。
a:task_struct
(1)每一个任务都有一个
b:mm_struct
(1)每个人物都有一个mm_struct 结构,内核用该结构表示内存地址范围(所有的mm_struct 描述符统一放在双向链表中,链表头对应于0进程的mm_struct ,可以通过全局变量ini_mm来访问该描述符)
(2)该结构部分代码
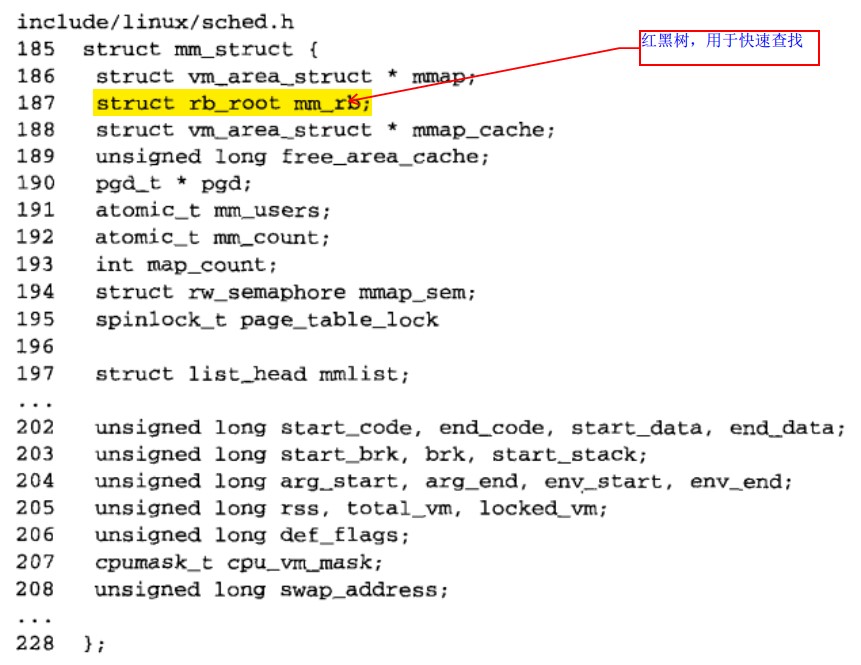
(3)结构体分析
1)mmap :进程对应的内存区描述符(vm_area_struct),被分配给链接于一个链表中的进程,通过mm_struct 中的mmap访问该链表。同时vm_area_struct 中的vm_next 将各个内存区描述符连接起来。
2)pgd:这是一个指针,指向存放该内存区中页的全局目录,通过该目录加上虚拟地址可以访问到物理地址。
3)mm_users:存放方位该内存进程的数量
4)mm_conut :是对mm_struct 的使用计数,如果为0,这可以回收页面。
5)map_count:存放进程地址空间中内存区数量,或者说是vm_area_struct描述符的数量。
6)start_code和end_code:用于存放进程代码段开始和结束地址(个人认为是虚拟地址)
7)start_data和end_data:存放初始化数据开始和结束地址(个人认为是虚拟地址)
8)start_brk和end_brk:堆栈的开始和结束地址
9)start_stack:进程栈的开始地址
10)arg_start和arg_end:指向传递给进程的参数的开始和结束地址
11)env_start和env_end:存放环境的开始和结束地址
c:vm_area_struct
该结构体定义了虚拟内存区域,因为对于一个进程来将,进程存在于不同的内存区,每个内存区都有对应的vm_area_struct。通常进程所使用到的虚存空间不连续,且各部分虚存空间的访问属性也可能不同。所以一个进程的虚存空间需要多个vm_area_struct结构来描述。在vm_area_struct结构的数目较少的时候,各个vm_area_struct按照升序排序,以单链表的形式组织数据(通过vm_next指针指向下一个vm_area_struct结构)。但是当vm_area_struct结构的数据较多的时候,仍然采用链表组织的化,势必会影响到它的搜索速度。针对这个问题,vm_area_struct还添加了vm_avl_hight(树高)、vm_avl_left(左子节点)、vm_avl_right(右子节点)三个成员来实现AVL树,以提高vm_area_struct的搜索速度。
(2)结构体部分代码

(3)结构体分析
1)vm_mm:所有的内存区间都属于进程地址空间,而地址空间由mm_struct表示,该指针指向所属进程的mm_struct
2)vm_start和vm_end:该内存区间的起始地址和结束地址
3)vm_next:指向所属于该进程空间的下一个内存区间
4)vm_ops:指向操作vm_area_struct 的函数集合,比如发生缺页异常的时候会调用该函数
<图解以上几个数据结构的关系>
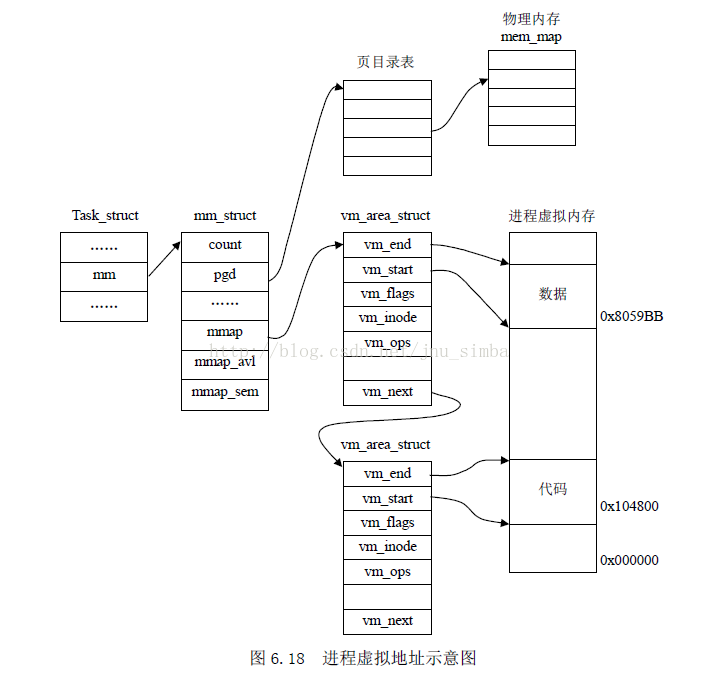
(4)mmap()函数与vm_area_struct 之间的关系
1) mmap调用实际上就是一个内存对象vma的创建过程, mmap的调用格式是:
void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset);
2)参数详解
其中start是映射地址, length是映射长度, 如果flags的MAP_FIXED不被置位, 则该参数通常被忽略, 而查找进程地址空间中第一个长度符合的空闲区域;Fd是映射文件的文件句柄, offset是映射文件中的偏移地址;prot是映射保护权限, 可以是PROT_EXEC, PROT_READ, PROT_WRITE, PROT_NONE, flags则是指映射类型, 可以是MAP_FIXED, MAP_PRIVATE, MAP_SHARED, 该参数必须被指定为MAP_PRIVATE和MAP_SHARED其中之一,MAP_PRIVATE是创建一个写时拷贝映射(copy-on-write), 也就是说如果有多个进程同时映射到一个文件上,映射建立时只是共享同样的存储页面, 但是某进程企图修改页面内容, 则复制一个副本给该进程私用, 它的任何修改对其它进程都不可见. 而MAP_SHARED则无论修改与否都使用同一副本, 任何进程对页面的修改对其它进程都是可见的.
3)mmap系统调用的实现过程是:
1.先通过文件系统定位要映射的文件;
2.权限检查, 映射的权限不会超过文件打开的方式, 也就是说如果文件是以只读方式打开, 那么则不允许建立一个可写映射;
3.创建一个vma对象, 并对之进行初始化;
4.调用映射文件的mmap函数, 其主要工作是给vm_ops向量表赋值;
5.把该vma链入该进程的vma链表中, 如果可以和前后的vma合并则合并;
6.如果是要求VM_LOCKED(映射区不被换出)方式映射, 则发出缺页请求, 把映射页面读入内存中.
5)munmap(void * start, size_t length):
该调用可以看作是mmap的一个逆过程. 它将进程中从start开始length长度的一段区域的映射关闭, 如果该区域不是恰好对应一个vma, 则有可能会分割几个或几个vma.
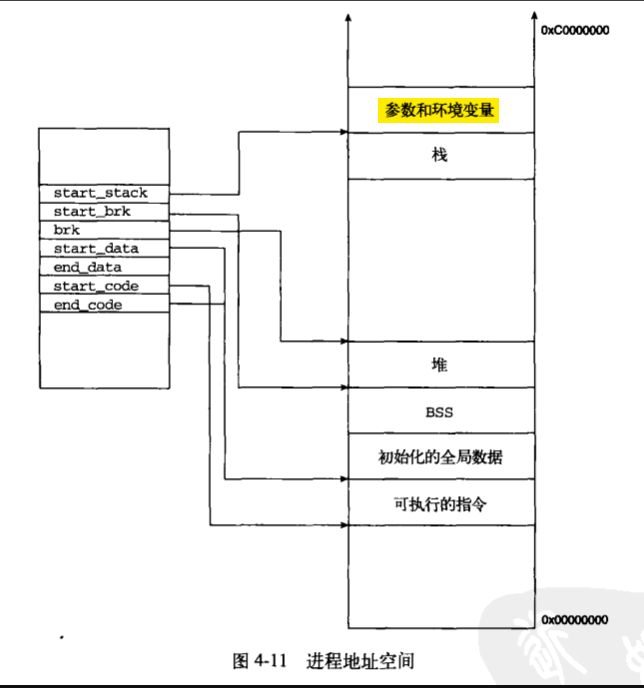
<进程在内存空间的分布>
当用户空间程序被载入内存后,其拥有了自己的线性地址空间,该空间被划分为各中内存区间,不同的区间拥有不同的功能。
a:text段
该段被称作代码段,存放的是程序的执行指令,拥有execute和read属性,mm_struct 中start_code和end_code保存了text段的起始地址。
b:data段
存放所有已经初始化的数据,包括静态分配的数据(static)和初始化的全局数据
c:gvar
存放未初始化的全局变量。
d:bss
存放未初始化的数据
e:堆
用于扩展进程的线性地址空间,当程序调用函数malloc()获得的内存置于该区间。mm_struct中的start_brk和end_brk用于记录该区间的起始和结束地址。
f:栈
该段包含已经分配内存的局部变量,当作函数调用的时候,函数的局部变量被压入栈,函数返回的时候,于函数相关的变量被弹出。mm_struct 中的start_stack记录栈的起始位置。
g:相关关系图
<虚拟地址转化到物理地址>
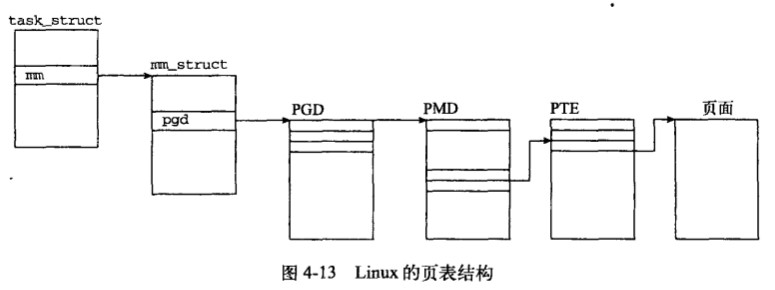
处理器只能操作物理地址,虚拟地址和对应的物理地址之间的转换需要借助内核中的页表来维护。页表对内存中的页面走向进行记录,在内核运行的整个生命期间,页表都放在内存中。Linux采用的是三级页表的分页机制,分别为:
a:PGD(page globle directory)
由mm_struct 中的pgd_t指定
b:PMD(page middle directory)
由数据类型pmd_t指定
c:PTE(page table)
由数据类型pte_t指定
d:三者之间的关系图如下
e:x86体系的转化过程详细分析
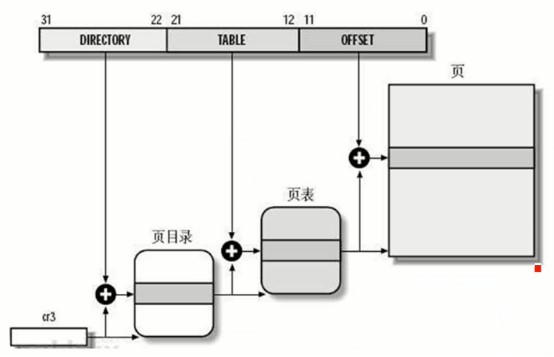
首先将32位的虚拟地址的高10位取出来作为偏移,这个偏移加上CR3寄存器里面的一级也表基地址,就是存储二级页表基地址的单元的地址,根据该单元存储的二级页表的基地址找到页表,然后取出32位虚拟地址的中间10位作为偏移,将二级页表的基地址和偏移相加得到物理页表的基地址的存储单元的基地址,从该单元取出物理也表达的基地址加上32位虚拟地址的低12位就是物理页表的物理地址。
<物理内存分配>
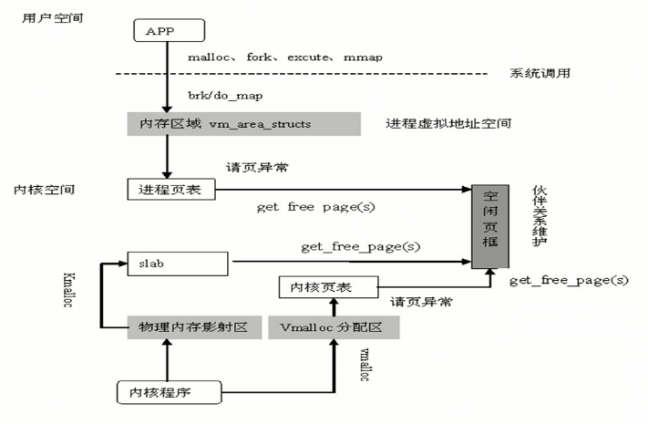
只有实实在在的去访问虚拟地址所对应的内存时,才会分配内存,如果不访问,则拿到的只是一个虚拟地址。
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
原文链接:https://www.qiquanji.com/post/8094.html
本站声明:网站内容来源于网络,如有侵权,请联系我们,我们将及时处理。

微信扫码关注
更新实时通知