今天主要就是介绍一下 CPU 中的多级缓存和乱序执行优化,为后面学习多线程做铺垫。先来理解一下 CPU 的结构,后面再说 Java 虚拟机的内存模型。
先放两张图看一下 CPU 和各级缓存、内存、硬盘之间的关系。
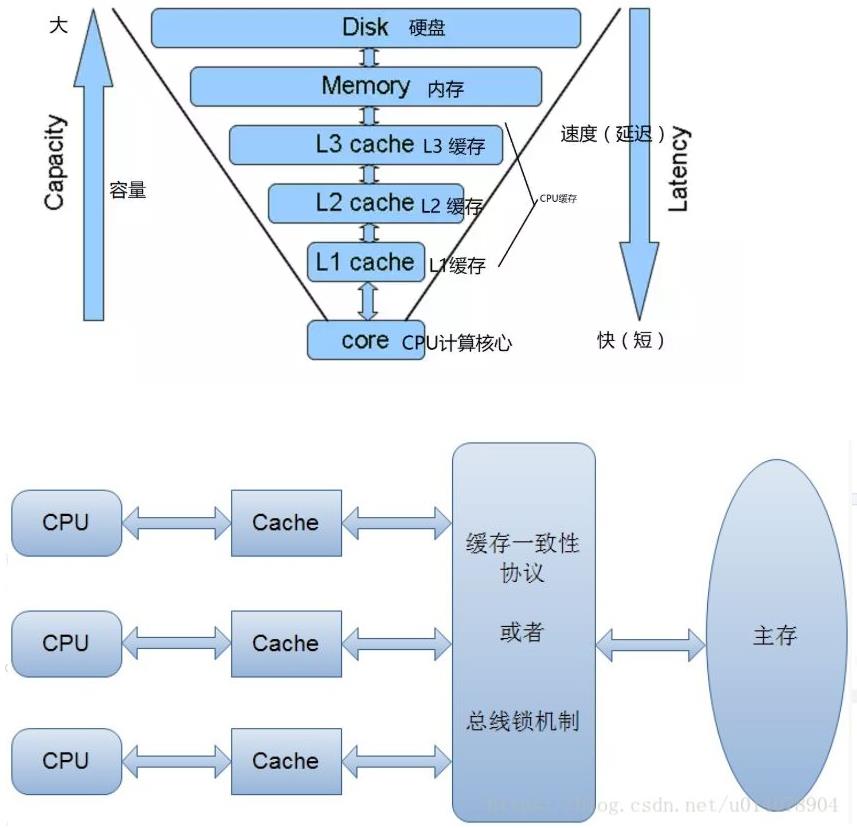
下面就来介绍一下为什么会出现多级缓存,以及会出现什么问题,CPU 又是如何解决的。
为什么会出现多级缓存呢?说的简单一点因为 CPU 的频率太快了,而若是没有缓存,直接读取内存中的数据又太慢了,我们不想让 CPU 停下来等待,所以加入了一层读取速度大于内存但小于 CPU 的这么一层东西,这就是缓存。
加入缓存之后,CPU 需要数据就问缓存要,缓存没有就从主存中读取,并保留一份在缓存中。下次读取就从缓存中读取,加快速度。
但是,我们经常听到 CPU 运行速度快,缓存次之,而内存慢一点,硬盘最慢。这又是为什么呢?
CPU 运行的快,那是因为一个时钟周期短,一个时钟周期是指机器码0和1变化,实质就是电信号一高一低之间所用的时间,这可都是电信号啊,电的速度能不快嘛!也就 10 纳秒左右吧,1 秒等于 10 的 9 次方纳秒。
下面介绍一下缓存和内存
目前缓存基本上都是采用 SRAM 存储器,SRAM 是英文 Static RAM 的缩写,它是一种具有静志存取功能的存储器,不需要刷新电路即能保存它内部存储的数据。不像 DRAM 内存那样需要刷新电路,每隔一段时间,固定要对 DRAM 刷新充电一次,否则内部的数据即会消失,因此 SRAM 具有较高的性能,但是 SRAM 也有它的缺点,即它的集成度较低,相同容量的 DRAM 内存可以设计为较小的体积,但是 SRAM 却需要很大的体积,这也是目前不能将缓存容量做得太大的重要原因。这中间也解释了为什么内存中的数据一断电就没有了。
而 RAM(随机读写存储器)的工作原理大致是当 CPU 读取主存时,将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上返回给 CPU。
磁盘慢就慢在它的读取是需要借助于磁头移动,这有寻址的过程,而这还是一个机械运动的过程,上面慢也是在和电信号打交道,而磁盘不仅需要电还需要摆臂,所以,最慢的就是它了。
再说一点,我们说的主存就是我们常说的内存,比方说我的电脑的内存是 12 G,磁盘的空间是 1 T。
整理一下就是,我们为了提高 CPU 的利用率,添加了多级缓存,但是呢,数据的读取和保存都要在主存上进行,若是单线程是没有问题的,一条路走下去,该读读该写写。
但是在多线程的情况下就会出现问题,因为每个线程都有自己的缓存,假如线程 1 从主存中读取到 x,并对其加 1 ,此时还没有写回主存,线程 2 也从主存中读取 x ,并加 1 ,它们是不知道对方的,也不可以读取对方的缓存。这时都将 x 写回主存,那此时 x 的值就少了 1 。
这也就是多线程情况下带有缓存的问题,数据出现问题了,怎么办呢?不能把缓存去掉吧,这时就需要一种协议,来保证不同的线程在读写主存数据时遵守某种规则以保证不会出现数据不一致的问题。这种协议有很多,其中用的比较多的是 MESI 协议,主要用来保证缓存的一致性。
MESI 为了保证多个缓存中共享数据的一致性,定义了 cache line 的四种状态,而线程对 cache line 的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的 cache line 状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。(M: modified E: Exclusive S: shared I: invalid)
CPU 中每个缓存行(caceh line)使用 4 种状态进行标记(使用额外的两位(bit)表示)。
M: 被修改(Modified)
该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它 CPU 读取请主存中相应内存之前)写回主存。当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive)
该缓存行只被缓存在该 CPU 的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它 CPU 读取该内存时变成共享状态(shared)。同样地,当 CPU 修改该缓存行中内容时,该状态可以变成 Modified 状态。
S: 共享的(Shared)
该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个 CPU 修改该缓存行中,其它 CPU 中该缓存行可以被作废(变成无效状态)。
I: 无效的(Invalid)
该缓存是无效的(可能有其它 CPU 修改了该缓存行)。
cache line 不同的状态之间可以相互转化,这也就是 MESI 协议的具体内容,比方说一个处于 M 状态的缓存行必须时刻监听所有试图读该缓存行相对应主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成 S 状态之前被延迟执行。
还有很多,就不一一说了。
再回头看看那个图是不是清晰多了,在 MESI 出现之前的解决缓存一致性的方案是总线锁机制,这种解决方案效率很低,锁住总线期间,其他 CPU 无法访问内存。
说完了 CPU 中的多级缓存,再来看看 CPU 中的乱序执行优化,什么意思呢,处理器为提高运算速度而做出违背代码原有顺序的优化。虽然顺序变了,但是执行的结果是不会变的。
举个例子,我要去买杯饮料喝,正常逻辑是这样的,去店里->点单->付钱->喝饮料。那其实我还可以在去店里的路上同时就把【点单付钱】一起搞定,又或者我先【点单】再去店里付钱拿饮料。
类比到 CPU 中也是这样,求 x + y = ? 我计算 x 的值,再计算 y 的值,其实可以一起执行,或是先计算 y 的值,当然为了提高运算速度,它会同时计算 x 和 y 的值,一个 CPU 中又不是只有一个逻辑计算的单元。
乱序优化就是这样,为了提高效率 CPU 做出的优化,这在单核的时候是不会有问题的,但是在多核时代又会出现问题。
再举个例子,线程 1 需要借组一个 flag 变量执行一段逻辑,你能用 C线程 2 来乱序优化一下,先执行逻辑而不看 flag 变量的值?这是肯定不行的。
行还是不行肯定有一套规则,这套规则也就是内存屏障,太高级了听不懂,换一种说法,就是说不同架构的处理器在其指令集中提供了不同的指令来发起内存屏障,对应在编程语言当中就是提供特殊的关键字来调用处理器相关的指令。结果就是有些指令能乱有些则不能!
好了,到这里就算把 CPU 级别的特性给说完了,这些知识对于我们理解 Java 内存模型(JMM) 以及多线程编程很有用。而 Java 内存模型就是借鉴了硬件的结构。
总结一下,在 CPU 中为了提高运行效率,加了多级缓存和乱序执行优化。加了多级缓存之后呢,会出现缓存不一致的情况,解决的办法就是定义了 MESI 等类似协议。对于乱序执行优化带来的问题,CPU 选择内存屏障来解决,即定义了一套指令集,什么样的指令不能执行乱序优化。
以上也就是介绍完了硬件的内存架构,看完了 CPU 中的骚操作,是不是迫不及待的想要看 Java 中的内存模型了,不要走开,下节更精彩!
原文链接:https://www.qiquanji.com/post/7680.html
本站声明:网站内容来源于网络,如有侵权,请联系我们,我们将及时处理。

微信扫码关注
更新实时通知