众所周知,在 CPU 的眼里只有 1 和 0,虽然简单,但它们却构造出了世界上人类最难理解的语言 —— 机器语言。
因此,想要让计算机运行你的代码,你必须将你的源代码“翻译”成 CPU 认识的语言才行。
下边小甲鱼以 GCC 为例,尝试给大家讲下编译器的工作流程!
要将 C 语言翻译成机器语言,简单来说需要两个步骤:编译 -> 链接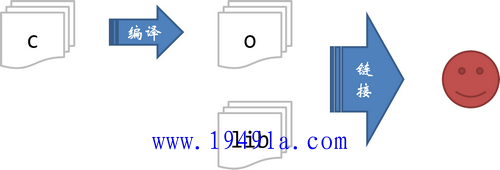
对于 GCC 来说,执行 gcc test.c 命令,其实相当于依次执行下面四个步骤:
预处理(Pre-Processing)-- 对 C 语言进行预处理,生成 test.i 文件
编译(Compiling)-- 将上一步生成的 test.i 文件编译生成汇编语言文件,后缀名为 test.s
汇编(Assembling)-- 将汇编语言文件 test.s 经过汇编,生成目标文件,后缀名为 test.o
链接(Linking)-- 将各个模块的 test.o 文件链接起来,生成最终的可执行文件
注:前三个步骤均属于编译过程。
先敲几行最简单的源代码:
#include <stdio.h>
#define FISHC "FishC.com"
int main(void)
{
printf("I love %s\n", FISHC); // 打印字符串
return 0;
}
预处理(Pre-Processing)
使用 -E 选项执行预处理命令并停下来,生成后缀为 .i 的预编译文件:
gcc -E test.c -o test.i
这时 GCC 将对各种预处理指令(#include、#define 和 #ifdef 这些以“#”开始的代码行)进行处理,并删除注释,添加行号以及文件名标识。
现在代码仍然是源代码文本形态,所以你可以使用 vi test.i 命令打开查看:
使用 G 命令跳转到末尾,看到注释被删除了,#define 宏定义也在这里进行了替换:
编译(Compiling)
编译就是将预处理完的文件,通过一系列的词法分析、语法分析、语义分析及优化后产生相应的汇编代码文件。
这一步使用 -S 选项来实现:
gcc -S test.i -o test.s
同样,使用 vi test.s 命令可以查看转换后的汇编代码:
汇编(Assembling)
汇编过程是将汇编代码转换为 CPU 认识的二进制文件,执行到这一步,这叫目标文件。
这一步使用 -c 选项来实现:
gcc -c test.s -o test.o
这时候你就无法使用 vi 来打开 test.o 文件了,因为是二进制编码,如果一定要使用文本模式打开的话,也只能是以乱码的形式呈现了:
查看二进制文件,正确的打开姿势是使用 xxd test.o 命令: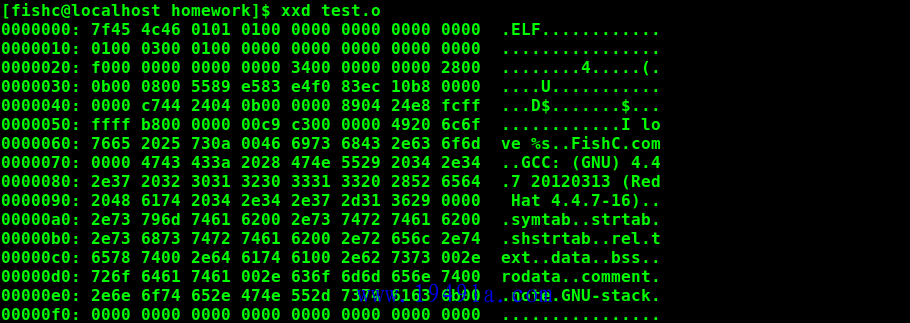
链接(Linking)
我们看到源代码中调用了 printf 函数,但并没有定义 printf 函数的实现过程,这是因为我们知道这是一个 stdio 的标准库函数。虽然在预处理(第一步)中,将 stdio.h 头文件导了进来,但那里边只有 printf 函数的声明而已: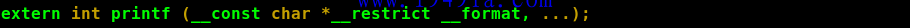
从程序员的角度看,函数库实际上就是头文件(.h)和库文件(.so 或 .a)的结合,头文件中声明函数,库文件中定义函数的实现。所以在最后一步的链接,就是把相关的库文件给链接进来(也就是把 printf 的实现代码添加进来)。
注:Linux 下的库文件分为两大类,分别是:动态链接库(通常以 .so 结尾)和静态链接库(通常以 .a 结尾)
执行 gcc test.o -o test 命令,生成最终的可执行文件:
注:此作乃小甲鱼写的很好的文章,然后就分享给大家了,好东西就要分享

微信扫码关注
更新实时通知