解决Hadoop启动后jps没有Datenode
执行start-dfs.sh后,或者执行datenode没有启动。很大一部分原因是因为在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令
这时主节点namenode的clusterID会重新生成,而从节点datanode的clusterID 保持不变导致的。
解决方法:
1.查看路径:
配置hadoop-2.6.4的各项文件(注意:路径不同,命令也不一样)
cd
cd hadoop/hadoop-2.6.4
cd etc/hadoop
gedit hdfs-site.xml //修改代码
找到如下代码:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/tianjiale/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/tianjiale/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<value> 里面的路径需要注意
2.查看namenode和datanode的clusterID是否相同。
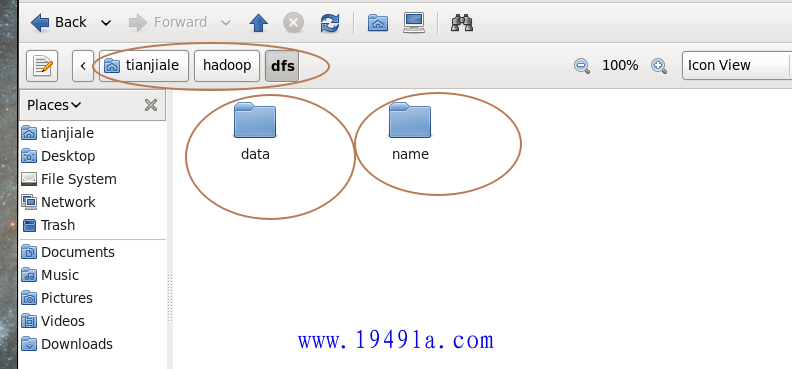{kind=link}
、
{kind=link}
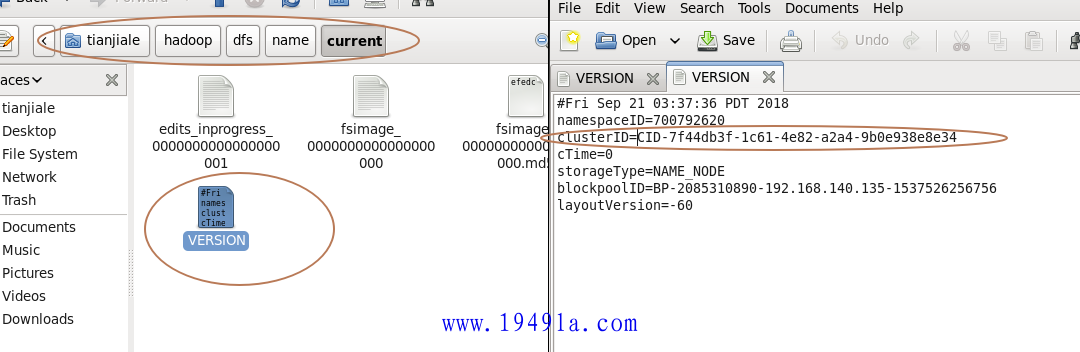{kind=link}
如果clusterID不相同,则将namenode的clusterID赋值给datanode的clusterID。
然后重新运行脚本start-dfs.sh.
最后jps查询看看。
就可以了
ps:我是这个办法成功了
微信扫码关注
更新实时通知