python用雅虎财经(yahoo)接口写简易爬虫获取A股上证所有股票(可以单独选择个股)历史数据
设计方案,分两步:
首先,获取上证所有股票名称和股票代码。
然后,从雅虎财经(yahoo)根据股票代码获取该股票的数据。注意上证股票代码后要加".ss"深证要加".sz"
下面是代码:
首先从爬取所有股票名和code到本地,文件名为huStock.pickle
import bs4 as bs import requests#python的http客户端 import pickle#用于序列化反序列化 def GetHuStock(): res = requests.get('https://www.banban.cn/gupiao/list_sh.html') #防止中文乱码 res.encoding = res.apparent_encoding #使用bsoup的lxml样式 soup = bs.BeautifulSoup(res.text,'lxml') #从html内容中找到类名为'u-postcontent cz'的div标签 content = soup.find('div',{'class':'u-postcontent cz'}) result= [] for item in content.findAll('a'): #这里写股票代码(这样可以挑选个股选择性下载数据) if '600673' in item.text: result.append(item.text) print(item.text) with open('huStock.pickle','wb') as f: pickle.dump(result,f)然后读取该文件,根据code逐一下载股票数据并存放到本地指定目录下,方便以后进一步分析
import datetime as dt import pandas as pd import pandas_datareader.data as web from matplotlib import style import matplotlib.pyplot as plt import os def GetStockFromYahoo(isHaveStockCode = False): if not isHaveStockCode: GetHuStock() with open('huStock.pickle','rb') as f: tickets = pickle.load(f,encoding='gb2312') if not os.path.exists('StockDir'): os.makedirs('StockDir') for ticket in tickets: arr = ticket.split('(') stock_name = arr[0] stock_code = arr[1][:-1]+'.ss' if os.path.exists('StockDir/{}.csv'.format(stock_name+stock_code)): print('已下载') else: DownloadStock(stock_name,stock_code) print('下载{}中...'.format(stock_name)) def DownloadStock(stockName,stockCode): style.use('ggplot') start = dt.datetime(1995,1,1) end = dt.datetime(2020,4,7) #根据股票代码从雅虎财经读取该股票在制定时间段的股票数据 df = web.DataReader(stockCode,'yahoo',start,end) #保存为对应的文件 df.to_csv('StockDir/{}.csv'.format(stockName+stockCode)) GetStockFromYahoo()下载后的数据效果如下:
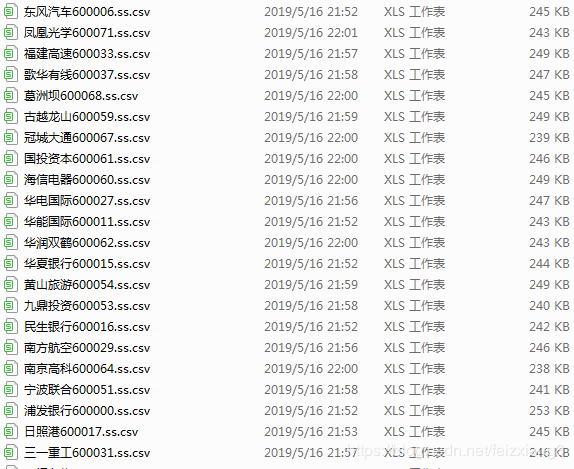{kind=link}
版权声明:本文为期权记的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.qiquanji.com/post/121.html
微信扫码关注
更新实时通知