c语言基础复习笔记
每一个c源程序都必须有,且只能有一个主函数(main函数)
符号常量:一般形式为:#define 标识符 常量
其中#define也是一条预处理命令(预处理命令都是以#开头),称为宏定义命令,其功能是把该标识符定义为其后的常量值
3.看到与和或的时候,要想到短路优先
3.字符值是以ASCLL码的形式存放在变量的内存单元之中的。
4.字符常量占一个字节的内存空间。字符串常量占的内存字节数等于字符串中字节数加1.增加的一个字节中存放字符“\o”(ASCLL码为0)。这是字符串结束的标志。
5.char型和short型参与运算时,必须先转换成int型。
c语言编译器,有符号和无符号相乘,可以进行运算的,但是结果会让你意外,所以在c++编译器设计时,就要求类型必须匹配,否则直接按语法错误进行处理
6.所有的浮点运算都是以双精度进行的,即使仅含float单精度量运算的表达式,也要先转换成double型,再作运算。 char型和short型参与运算时,必须先转换成int型
7.\的意思就是把下一行当作是上一行的延续
eg:int main(){
print\
f("");
return 0;
}就等于
int main(){
printf("");
return 0;
}
\的这个作用也可以用在字符串里面
变量
1.变量的声明和变量的定义
变量的声明:用于向程序表明变量的类型和名字
变量的定义:用于为变量分配存储空间,还可为变量指定初始值。程序中,变量有且仅有一个定义
8.变量的意义就是确定目标并提供存放的空间
9.变量命名第一个字母必须是字母或者下划线开头,不能使用关键字来命名变量
取值范围
10.int,char在默认情况下是带符号的,signed型,说明最高位是符号位
11.无符号int型即unsigned int 型打印的时候要用%u
12.事实上计算机是用补码的形式来存放整数的值
算术运算符
13,一个浮点型的结果,强行用整形%d打印出来就会乱码
{kind=link}
逻辑运算符
14.短路求值又称最小化求值,是一种逻辑运算符的求值策略。只有当第一个运算数的值无法确定逻辑运算的结果时,才对第二个运算数进行求值,c语言对于逻辑与和逻辑或采用短路求值的方式
{kind=link}
{kind=link}
数组
14.数组中未被赋值的元素自动初始化为0
15.如果数组只是被定义,没有初始化,那数组里面的元素就是一堆乱的数字
16.c99增加了一种新特性:指定初始化的元素。这样就可以只对数组中的某些指定元素进行初始化赋值,而未被赋值的元素自动初始化为0
eg:int a[10]={[2]=2,[7]=8};
指针
17.指针都是4个字节,因为指针里面都是存放的地址,所以sizeof(指针)=4
18.%p是打印地址
19.数组名只是一个地址,而指针是一个左值
20.C 语言的术语 lvalue 指用于识别或定位一个存储位置的标识符。(注意:左值同时还必须是可改变的)
数组指针
21.eg:int (*p2)[5];
p2指向的是整个int数组
首先我们先来了解一下一个知识eg:
int temp[5]={1,2,3,4,5};
int (*p2)[5]=&temp;//temp是数组的第一个元素的地址,而&temp是整个数组的地址
int i;
for(i=0;i<5;i++){
printf("%d\n",*(*p2+i));//p2指向的是整个数组的地址,而*p2指向的是第一个元素的地址
}
根据上面的代码做一下测试
#include<stdio.h>
int main(){
int temp[5];
int (*p2)[5]=&temp;
printf("%p,%p\n",temp,p2);
printf("%p,%p",temp+1,p2+1);
return 0;
}
运行结果是
0060FF10,0060FF10
0060FF14,0060FF24请按任意键继续. . .
说明了什么呢?说明temp+1和p2+1的跨度不一样,p2+1就相当于二维数组的第二行,所以就不能 int (*p2)[5]=temp;
而上上面那个程序中的printf("%d\n",*(*p2+i));中的*(*p2+i))其实可以理解成*(*(p2+0)+i))
然后就明白了数组指针liao
指针和数组和二维数组
22.a[n] 表示 *(a+n),用 a[n][m] 表示 *(*(a+n)+m),
23.int a[5];&a 是整个数组的首地址,a是数组首元素的首地址,其值相同但意义不同。
24.
#include <stdio.h>
int main()
{
int arry[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};
printf("%d,%d\n", arry, *arry); //0行首地址 0行0列元素地址
printf("%d,%d\n", arry[0], *(arry+0)); //0行0列元素地址 0行0列元素地址
printf("%d,%d\n", &arry[0], &arry[0][0]); //0行首地址 0行0列元素地址
printf("%d,%d\n", arry[1], arry + 1); //1行0列元素地址 1行首地址
printf("%d,%d\n", &arry[1][0],*(arry + 1) + 0); //1行0列元素地址 1行0列元素地址
printf("%d,%d\n", arry[2], *(arry + 2)); //2行0列元素地址 2行0列元素地址
printf("%d,%d\n", &arry[2], arry + 2); //2行首地址 2行首地址
printf("%d,%d\n", arry[1][0], *(*(arry + 1) + 0));//1行0列元素的值 1行0列元素的值
printf("%d,%d\n", *arry[2], *(*(arry + 2) + 0)); //2行0列元素的值 2行0列元素的值
return 0;
}
-214132016,-214132016
-214132016,-214132016
-214132016,-214132016
-214132000,-214132000
-214132000,-214132000
-214131984,-214131984
-214131984,-214131984
5,5
9,9
void指针和NULL指针
void指针我们把它称之为通用指针,就是可以指向任意类型的数据。也就是说,任意类型的指针都可以赋值给void指针
int num=1024;
int *pi=#
char *ps="FishC";
void *pv;
pv=pi;
printf("pi:%p,pv:%p\n",pi,pv);
pv=ps;
printf("p:%p,pv:%p\n",pi,pv");
25.当你还不清楚要将指针初始化为什么地址时,请将它初始化NULL;要不然它就是野指针
int *p1;//野指针
int *p2=NULL;//正确的
26.NULL和NUL的区别:
NULL用于指针和对象,指向一个不被使用的地址;而NUL(即'\0')表示字符串的结尾
const
27.int num=520;
conts int cnum =80;
conts int *p=&cnum;
其中p的值可以改变,而*p的值不可以改变,因为conts修饰是int,说明p指向的是一个不可以被修改的整形,即
p=num;//是正确的
*p=1024;//是错误的
如果是int * conts p=&cnum;//说明conts修饰的是p,所以指针p所指向的地址是不可以改变的,但是*p的值是可以改变的,即
p=num;//是错误的
*p=1024;//是正确的
数组作为函数参数时
28.函数的类型就看函数的返回值
288.函数在声明的时候可以不写参数的名字,但参数类型是必须要写上的;还有一个就是函数原型的参数名还可以随便写一个名字,不必与形式参数相匹配,
即void func(int a,int b);
void func(int d,int e){
.....
}
29.当数组作为函数参数时,实际上实参传的是一个地址给形参
void get_array(int b[10]);
void get_array(int b[10]){
printf("sizeof b: %d",sizeof(b));
}
int main(){
int a[10]={1, 2, 3,4,5,6,7,8,9,0};
printf("sizeof a: %d\n",sizeof(a));
get_array(a);
return 0;
}
运行结果是
sizeof a: 40
sizeof b: 4//因为a传给形参只是一个地址,一个地址就是占4个字节
可变参数
va_list 、va_start、 va_arg、 va_end
通过一个例子来说明这几个的用法
#include<stdio.h>
#include<stdarg.h>//上面说到的类型va_list和三个宏va_start、 va_arg、 va_end必须包含的头文件
int sum(int n,...);
int sum(int n,...){
int i,sum=0;
va_list vap;//定义一个参数列表
va_start(vap,n);//初始化参数列表,vap就是上面定义的参数列表,n就是函数的第一个参数
for(i=0;i<n;i++){
sum+=va_arg(vap,int);//获取参数列表的下一个参数,
}
va_end(vap);//清空va_list可变参数列表,参数列表访问完以后,参数列表指针与其他指针一样,必须收回,否则出现野指针。
return sum;
}
int main(){
int result;
result=sum(3,1,2,3);
printf("result=%d\n",result);
}
运行结果是result=6
另一个例子:
#include <stdio.h>
#include <stdarg.h>
void functestarg(int,...);
int main ()
{
functestarg(1,2,3,4,5,6,7,8,9,10,0);
return 0;
}
void functestarg(int a,...)
{
va_list argpointer;
va_start(argpointer, a);
int argument;
int count = 0;
while(0 != (argument = va_arg(argpointer, int)))
{
printf("parameter%d:%d\n",++count,argument);
}
}
运行结果:
parameter1:2
parameter2:3
parameter3:4
parameter4:5
parameter5:6
parameter6:7
parameter7:8
parameter8:9
parameter9:10
指针函数
1.#include<stdio.h>
char *getWord(char c);
char *getWord(char c){ //注意这里字符串返回用了字符指针,因为字符串返回的是第一个字母的地址(C语言约定俗//成的规则),之所以是这样是因为字符串有结束符
switch(c){
case'A':return "Apple";//还有这里要注意用的是return,而不是经常写的break。仔细想想这样写很明智
case'B':return "Banana";
case'C':return "Cat";
case'D':return "Dog";
default:return "None";
}
}
int main(){
char input;
printf("请输入一个字母:");
scanf("%c",&input);
printf("%s\n",getWord(input));
return 0;
}
2.不要返回局部变量的指针
#include<stdio.h>
char *getWord(char c);
char *getWord(char c){
char str1[]="Apple";
char str2[]="Banana";
char str3[]="Cat";
char str4[]="Dog";
char str5[]="None";
switch(c){
case'A':return str1 ;
case'B':return str2 ;
case'C':return str3;
case'D':return str4;
default:return str5;
}
}
int main(){
char input;
printf("请输入一个字母:");
scanf("%c",&input);
printf("%s\n",getWord(input));
return 0;
}
运行会出现警告,但是运行错误
函数的局部变量是存放在栈里面的,函数结束,栈就销毁,所以返回局部变量就会出现错误,因为你返回的局部变量已经不存在了
函数指针
1.函数名就是地址,规定的
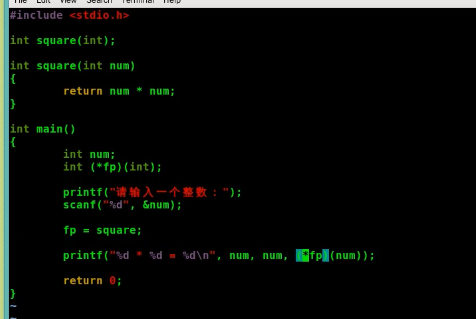{kind=link}
其中的int (*fp)(int);//是定义一个函数指针,fp是指向一个参数是int,返回值是int的函数
2.函数指针作为参数的例子:
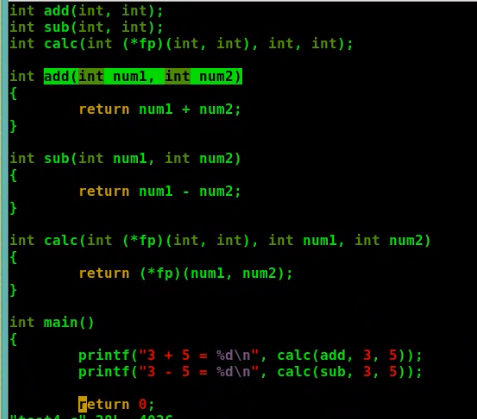{kind=link}
3.函数指针作为返回值的例子
{kind=link}
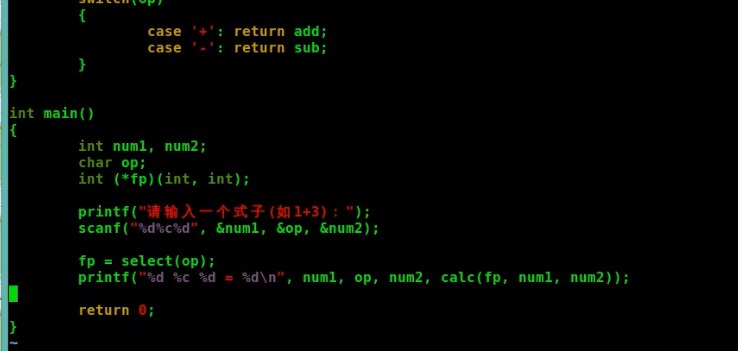{kind=link}
其中的int (*select(char))(int,int);//因为这些符号都是有优先级和结合性的,看运算符的优先级和结合性表,所以从左到右,select是函数名,参数是char,然后我们把已知的去掉就剩下int (*)(int,int);,就发现原来select函数返回的是一个函数指针,这个函数指针指向带两个int参数,返回值是int的函数
全局变量
0.全局变量从被定义时候开始,知道程序退出才被释放
1.如果不对全局变量进行初始化,那么他会自动初始化为0
2.如果在函数的内部存在一个与全局变量同名的局部变量,编译器并不会报错,而是在函数中屏蔽全局变量,也就是在函数中,全局变量不起作用
3.extern关键字
用extern关键字告诉编译器:这个变量我在后边定义了,你先别着急报错
例如:
void func(){
count++;
}
int count =0;
//后面的主函数就省略了
这样写的话编译器就会报错说count变量没有被声明
而这样写的话就不会报错
void func(){
extern int count;
count++;
}
int count =0;
4.局部变量即是定义又是声明
链接属性
1.首先要了解文件作用域是什么,
文件作用域:任何在代码之外声明的标识符都是具有文件作用域,作用范围是从它们的声明位置开始,到文件的结尾处都是可以访问的,比如全局变量,函数名(因为函数名本身也是在代码块之外的,所以函数名也是具有文件作用域)
2.接下来要知道为啥有链接属性这个东西
在大型程序中,会由很多源文件构成,会把代码写在不同文件里面,那么在不同文件里面同名标识符编译器是如何处理的,这时候就要看链接属性了
3.在c语言里面链接属性有三个:
~external(外部的) 多个文件中声明的同名标识符表示同一个实体
~internal(内部的) 单个文件中声明的同名标识符表示同一个实体
~none(无) 声明的同名标识符被当作独立不同的实体
只有具备文件作用域的标识符才能拥有external或者internal的链接属性,其他作用域的标识符都是none属性。默认情况下,具备文件作用域的标识符拥有external属性,也就是说该标识符允许跨文件访问。
可以使用static关键字可以使得原先拥有external属性的标识符变为internal属性,并且使用static关键字修改链接属性,只对具有文件作用域的标识符生效(对其他作用域的标识符是另一种功能),链接属性只能修改一次
生存期
1.静态存储期:
具有文件作用域的变量属于静态存储期,属于静态存储期的变量在程序执行期间将一直占据存储空间,直到程序关闭才释放
2.自动存储期:
具有代码块作用域的变量一般情况下属于自动存储期,属于自动存储期的变量在代码块结束时将自动释放存储空间。
存储类型
存储类型其实是指存储变量值的内存类型,分别有5种:
auto:在代码块中声明的变量默认的存储类型就是自动变量,使用关键字auto来描述,可以省略不写,因为是默认的; 那什么时候写上auto比较好呢?当你想强调局部变量屏蔽同名的全局变量的时候,你可以在同名的局部变量前加auto,使你的代码更加清晰
register(寄存器变量):当一个变量声明为register,那么该变量就有可能被存放于cpu的寄存器中,记住是有可能,因为cpu的寄存器存储空间是有限的,当该变量不被存放在cpu的寄存器时,此变量就变的和普通的自动变量一样;当你将变量声明为寄存器变量,那么你就没办法通过取址运算符获得该变量的地址,因为cpu的寄存器的地址在默认情况下是不被获取的
static:当static修饰局部变量的时候,此局部变量的生存期与全局变量一样,直到程序结束才释放
extern
typedef
递归汉诺塔问题
对于游戏的玩法,我们可以简单分解为三个步骤
-将前63个盘子从x移动到y上
-将最底下的第64个盘子从x移动到z上
-将y上的63个盘子移动到z上
void hanoi(int n,char x,char y,char z){
if(n==1){
printf("%c-->%c\n",x,z);
}else{
hanoi(n-1,x,z,y);
printf("%c-->%c\n",x,z);
hanoi(n-1,y,x,z);
}
}
快速排序
思路就是:一个未排序数据,首先选择中间元素作为基准点,再从左往右找到大于等于基准点的元素,从右往左找到小于等于基准点的元素,然后两个元素进行互换,然后继续,直到i>j,第一趟结束,此时分成左右两个队列,左边的队列的元素都比基准点小,右边的队列的元素都比基准点大,然后再用同样的办法对这两个队列进行排序
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
小甲鱼视频的截图
内存管理方式
malloc:申请动态内存空间(内存空间是连续的)
函数原型:void *malloc(size_t size);如果函数调用成功,返回一个指向申请的内存空间的指针,由于返回类型是void 指针(void *),所以它可以被转换成任何类型的数据;如果函数调用失败,返回值是NIULL。另外,如果size参数设置为0,返回值也可能是NULL(因为编译器不一样,可能结果就不一样),但这并不意味着函数调用失败;注意的一个点:malloc函数申请的内存空间是在堆里面的,对于堆来说,如果不主动释放堆里面的内存资源的话,那么堆上的内存资源永远存在,所以我们当我们不使用这块内存的时候,请手动主动的去释放这块内存资源,否则可能导致内存泄漏;
eg:
int *ptr;
ptr=(int *)malloc(sizeof(int));
free:释放动态内存空间
free函数原型:void free(void *ptr);
free函数释放ptr参数指向的内存空间。该内存空间必须是由malloc,calloc或realloc函数申请的,否则,该函数将导致未定义行为。如果ptr参数是NULL,则不执行任何操作。注意:该函数并不会修改ptr参数的值,所以调用后它仍然指向原来的地方(变为非法空间),但是ptr此刻指向的是一个垃圾的地址,没有任何意义
eg:
free(ptr);
printf("%d",*ptr);//打印出来的值不再是理想认为的值,有可能是0,可能是其他值
导致内存泄漏主要有两种情况:
---用完内存块没有及时使用free函数释放
---丢失内存块地址,例子:
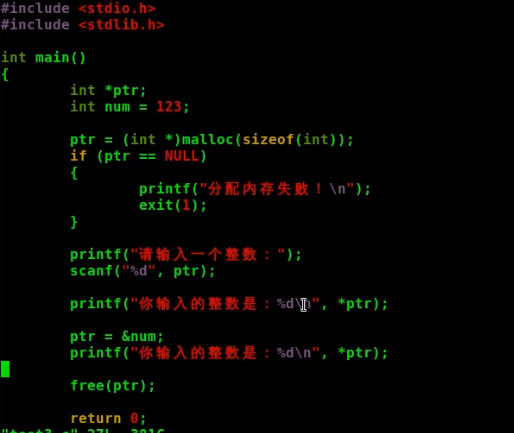{kind=link}
ptr开始的时候指向一个malloc申请的地址,后面变成指向一个局部变量,那么原来malloc申请的内存地址就被丢失了,找不到了,并且更严重的是free一个局部变量,也会出现错误
{kind=link}
{kind=link}
realloc:重新分配内存空间
如果空间不够,先按照newsize指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来ptr所指内存区域(注意:原来指针是自动释放,不需要使用free),同时返回新分配的内存区域的首地址。即重新分配存储器块的地址。
{kind=link}
{kind=link}
{kind=link}
看一个小甲鱼写的例子:
{kind=link}
{kind=link}
c语言的内存布局
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
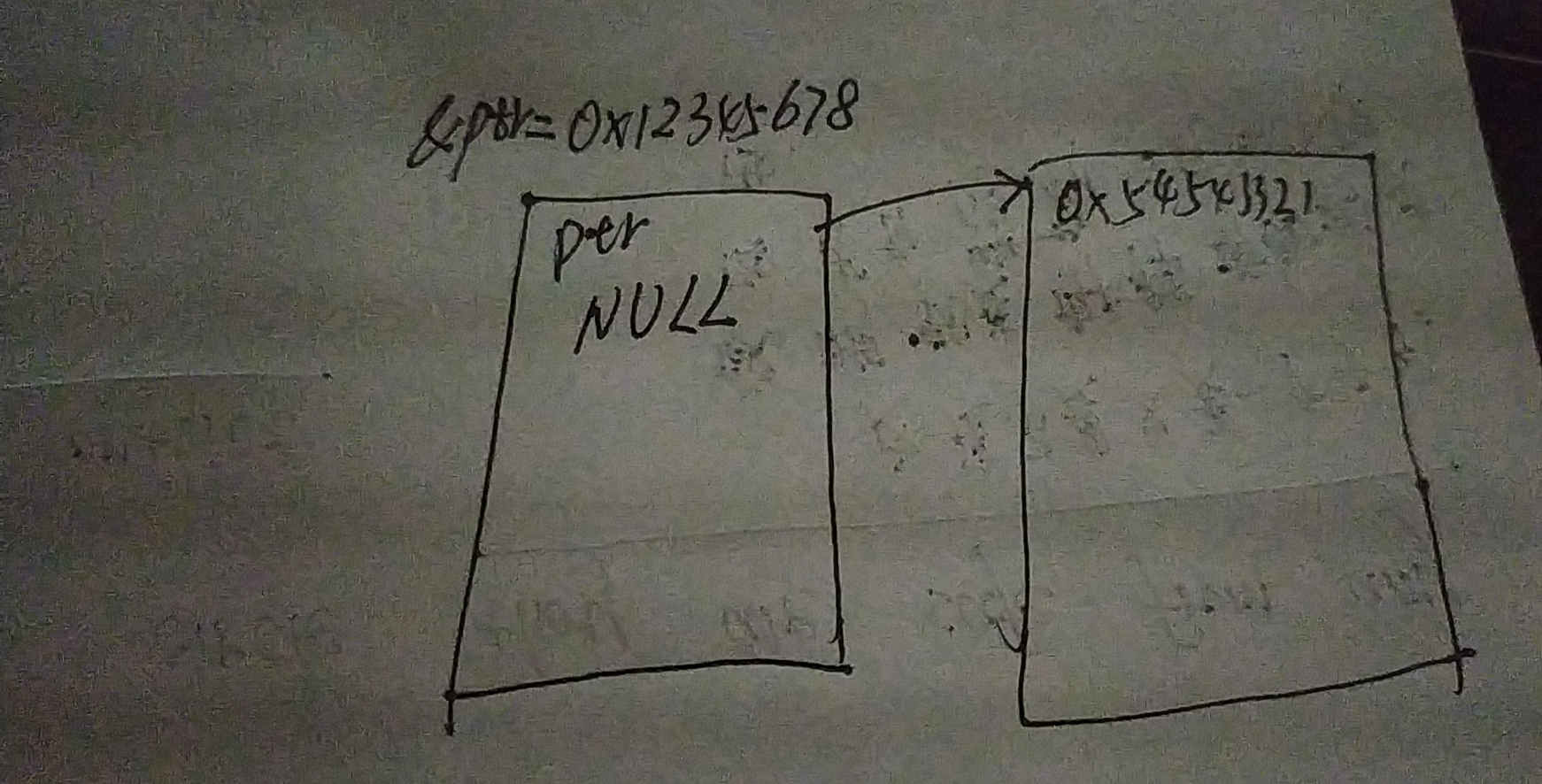
其中&prt1是在栈上,而prt1是在堆上
看下面这个图就明白了
{kind=link}
图上的地址是假设的
高级宏定义
预处理包括文件包含,宏定义,条件编译,预处理完成之后才进行文件的编译;
宏定义:
1.其中的宏定义只进行替换,不进行计算,也不做表达式的求解,编译器也不会对宏定义进行语法检查(因为编译工作的任务之一就是语法检查)
2.宏定义的作用域是从定义的位置开始到整个程序结束,我们可以用#undef来终止宏定义的作用域
eg:
#define PI 3.14
....
#undef PI
.....
3.宏定义可以嵌套,意思就是在一个宏定义中可以使用另一个宏
#define PI 3.14
#define R 3
#define V PI*R*R*4/3
4.宏定义可以带参数,并且记得加括号
eg:#define SUEH(x) ((x)*(x))//建议少用,因为容易出bug
举个会出现问题的例子:
#include<stdio.h> #define SWW(x) ((x)*(x)) int main(){ int i=1; while(i<=100){ printf("%d的平方是%d,,,,,%d\n",i-1,SWW(i++),i); } return 0; }猜一下结果会是多少?
结果公布
2的平方是1,,,,,1
4的平方是9,,,,,3
6的平方是25,,,,,5
8的平方是49,,,,,7
10的平方是81,,,,,9
12的平方是121,,,,,11
14的平方是169,,,,,13
16的平方是225,,,,,15
18的平方是289,,,,,17
20的平方是361,,,,,19
22的平方是441,,,,,21
24的平方是529,,,,,23
26的平方是625,,,,,25
28的平方是729,,,,,27
30的平方是841,,,,,29
32的平方是961,,,,,31
34的平方是1089,,,,,33
36的平方是1225,,,,,35
38的平方是1369,,,,,37
40的平方是1521,,,,,39
42的平方是1681,,,,,41
44的平方是1849,,,,,43
46的平方是2025,,,,,45
48的平方是2209,,,,,47
50的平方是2401,,,,,49
52的平方是2601,,,,,51
54的平方是2809,,,,,53
56的平方是3025,,,,,55
58的平方是3249,,,,,57
60的平方是3481,,,,,59
62的平方是3721,,,,,61
64的平方是3969,,,,,63
66的平方是4225,,,,,65
68的平方是4489,,,,,67
70的平方是4761,,,,,69
72的平方是5041,,,,,71
74的平方是5329,,,,,73
76的平方是5625,,,,,75
78的平方是5929,,,,,77
80的平方是6241,,,,,79
82的平方是6561,,,,,81
84的平方是6889,,,,,83
86的平方是7225,,,,,85
88的平方是7569,,,,,87
90的平方是7921,,,,,89
92的平方是8281,,,,,91
94的平方是8649,,,,,93
96的平方是9025,,,,,95
98的平方是9409,,,,,97
100的平方是9801,,,,,99
会不会看到很诧异???为啥第一行是2的平方是1,,,,,1?因为函数调用参数入栈的顺序是从右往左,并且在SWW里面有两个i++,所以结果才会出现2的平方是1,,,,,1,接下来的输出也是错误的,所以你懂得
接下来了解一下内联函数
举个例子说明
{kind=link}
当程序执行解析到printf函数中的函数square(i++)的时候,程序就发现这个函数是内联函数(加个inline在函数前面就变成内联函数),然后就直接把这个内联函数的所有代码直接在printf函数中的函数square(i++)这个位置展开,这样做的好处就是第一避免了宏定义的缺点,第二就是100次循环,不用开启100个函数栈,提高了效率。
{kind=link}
{kind=link}
#和##
#和##是两个预处理运算符
1.在带参数的宏定义中,#运算符后面应该跟一个参数,预处理器会把这个参数转换为一个字符串,举个例子就明白了
#include<stdio.h> #define STR(s) # s int main(){ printf(STR(Hello %s num =%d),STR(Fishc),520); return 0; }看代码的时候是不是觉得这个是错的,但是是完全正确的
运行结果:Hello Fishc num =520请按任意键继续. . .
就是把STR里面的东西变成一个字符串,即
STR(Hello %s num =%d)
相当于
"Hello %s num =%d"
所以str在printf里面编译器才不会报错
2.##运算符被称为记号连接运算符,比如我们可以使用##运算符连接两个参数,例子
{kind=link}
运行结果是250
3.综合运用,带参数的宏定义使用可变参数
例子:#define SHOWLIST(...) printf(# __VA_ARGS__)
其中...表示使用可变参数,__VA_ARGS__在预处理中被实际的参数集所代替
#include<stdio.h>
#define AA(...) printf(# __VA_ARGS__)
int main(){
AA(FishC,520,3.14\n);
return 0;
}
运行结果就是
FishC,520,3.14
4,可变参数可以支持是空的
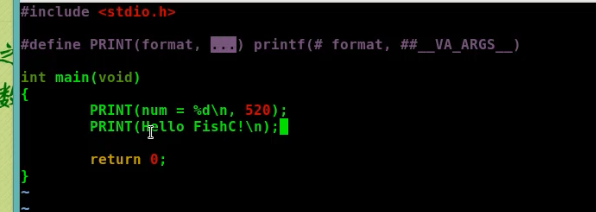{kind=link}
运行结果是:
num=520
Hello FishC!
结构体
两个结构体类型一样的结构体之间可以用赋值号进行赋值
typedef
0.相对于宏定义的直接替换,typedef是对类型的封装
定义一种类型的别名,而不只是简单的宏替换。可以用作同时声明指针型的多个对象。比如:
char* pa, pb; // 这多数不符合我们的意图,它只声明了一个指向字符变量的指针,
// 和一个字符变量;
以下则可行:
typedef char* PCHAR; // 一般用大写
PCHAR pa, pb; // 可行,同时声明了两个指向字符变量的指针
虽然:
char *pa, *pb;
也可行,但相对来说没有用typedef的形式直观,尤其在需要大量指针的地方,typedef的方式更省事。你不用像下面这样重复定义有81个字符元素的数组:
char line[81];
char text[81];
只需这样定义,Line类型即代表了具有81个元素的字符数组,使用办法如下:
typedef char Line[81];
Line text,line;
例二:
void (*signal(int,void(*)(int)))(int);
同样地,使用typedef可以简化上面的函数声明:
typedef void (*HANDLER)(int);
HANDLER signal(int ,HANDLER);
记住,typedef是定义了一种类型的新别名,不同于宏,它不是简单的字符串替换。比如:
先定义:
typedef char* PSTR;
然后:
int mystrcmp(const PSTR, const PSTR);
const PSTR实际上相当于const char*吗?不是的,它实际上相当于char* const。
原因在于const给予了整个指针本身以常量性,也就是形成了常量指针char* const。
简单来说,记住当const和typedef一起出现时,typedef不会是简单的字符串替换就行。
共同体和枚举类型
把结构体的struct改成union就是共用体了
共用体的所有成员共享同一个内存地址
共用体一次只能初始化一个共用体成员,因为共用体的所有成员共享同一个内存地址
共同体各成员共用一块内存空间,并且同时只有一个成员可以得到这块内存的使用权(对该内存的读写),各变量共用一个内存首地址。因而,共同体比结构体更节约内存。一个union变量的总长度至少能容纳最大的成员变量,而且要满足是所有成员变量类型大小的整数倍。举个例子
#include<stdio.h>
//联合体
union u1
{
char a;
int b;
short c;
}U2;
//主函数
int main(){
U2.a='a';
printf("%c%c\n",U2.b,U2.c);//输出aa
U2.a='b';
printf("%c%c\n",U2.b,U2.c);//输出bb
U2.b=0x4241;
printf("%c%c\n",U2.a,U2.c);//输出AA
return 0;
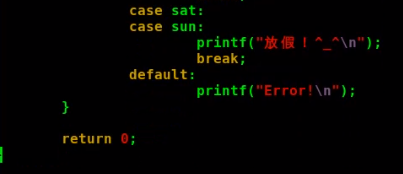
}如果一个变量只有几种可能的值,那么就可以将其定义为枚举类型
定义枚举变量
enum 枚举类型名称 枚举变量1,枚举变量2;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
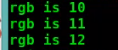
枚举里面的成员是个整数int常量,其第一个成员的值默认为0,接下来的成员的值逐个加1;如果不想其值为0;则可像上面那个例子一样;需要注意的是枚举成员的值不可以被改变
{kind=link}
{kind=link}
位域
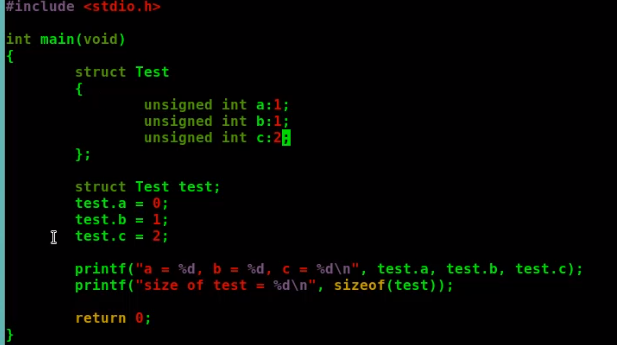
使用位域的做法是在结构体定义时,在结构体成员后面使用冒号(:)和数字来表示该成员所占的位数
{kind=link}
3.位域成员可以没有名称,只要给出数据类型和位宽即可
4.因为内存是以字节位单位,位域是字节的一部分,所以不能对位域进行取址运算
重点
c语言并没有规定一个字节占几位,不同的编译器不同的环境都不一样
文件
{kind=link}
打开方式要区分文本模式和二进制模式的原因
{kind=link}
fscanf和fprintf一般读入的是文本,通常不用fscanf和fprintf对二进制文件进行读入,输出,如果想写的文本的内容是可见的,就使用fscanf和fprintf。
而fread和fwrite则经常被用在对二进制文件的读入,输出。
需要了解的函数:ftell(用来返回当前文件指针的位置),rewind(将文件指针设置在流的开头),fseek
{kind=link}
{kind=link}
还有函数ferror(错误指示器),clearerr(可以人为地清除文件末尾指示器和错误指示器的状态)
{kind=link}
最近有心无力就这样了,不明白就再回去看视频或者搜索了
IO缓冲区
{kind=link}
setvbuf函数可以设置这些是缓冲模式的其中一种
微信扫码关注
更新实时通知